
M. Kemal Sonmez; Advisor: J. Baras
Problem
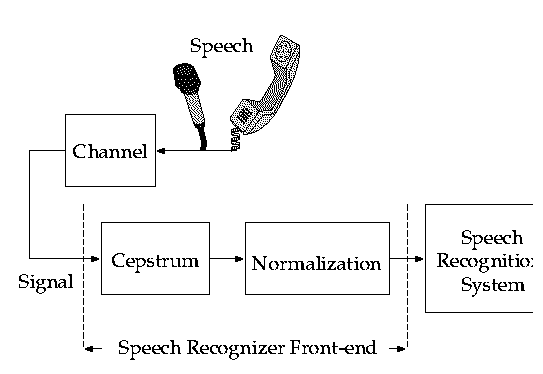
Current speech recognition/speaker identification systems exhibit an unacceptable degradation in performance when they are trained and tested in different environments (different microphones, channels or acoustical backgrounds). Normalization techniques to remove the discrepancy between the training and test performances are needed.
Significance
Real world applications which use speech recognition user interfaces are of great interest to the information industry. Texas Instruments Speech Research Laboratory, in particular, is developing several applications for speech recognition and speaker identification. Any practical application of speech recognition must perform satisfactorily in a variety of environments (different handsets, microphones, office environment, car phones, etc.). The algorithm developed in this work is an unsupervised adaptation algorithm which attempts to solve the normalization problem for a variety of unknown environments.
Approach
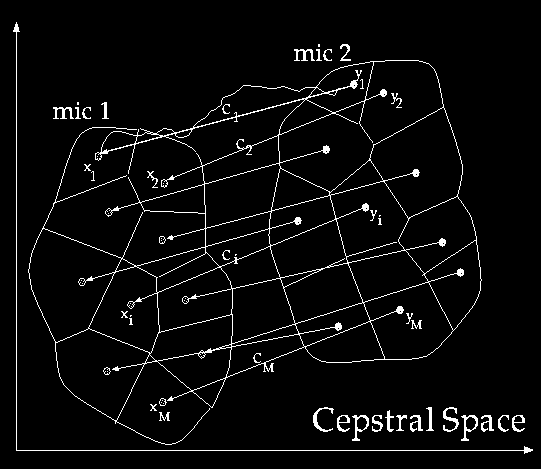
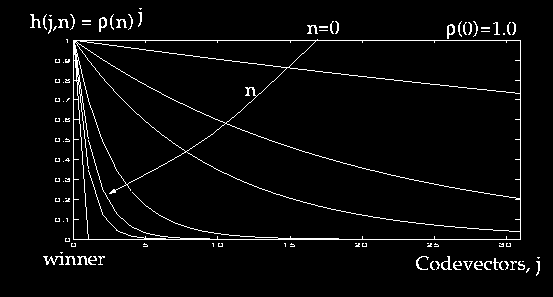
Basic idea is to compute normalization vectors by comparing histograms of the training and test microphone cepstrum distributions. The training microphone distribution is estimated by vector quantization (VQ). Unknown test microphone distribution is progressively estimated by a variant of Kohonen learning: Prior estimate for the test microphone VQ codebook is the training microphone codebook. Finer estimates are obtained by competitive learning with increasing resolution as the data arrive. The neighborhoods used for the Kohonen updates are those inherent in the training microphone VQ codebook. Corrections are made progressively for each data frame with the available estimate at the time of arrival. With a proper choice of parameters and resolution schedule, the test microphone codebook converges to the true distribution and efficient normalization is achieved.
How the algorithmworks
In the initial stage of the normalization, when the resolution is very low all the code vectors are updated equally strongly, resulting in a progressive equivalent of the popular Cepstral Mean Normalization algorithm. As the confidence in the identity of the winning code vector increases, resolution is increased and finer adjustments are made. Asymptotically and the algorithm becomes simple competitive learning which is still capable of tracking slow variations with a small [[daggerdbl]].
Experiment
PCU, CMR and RASTA algorithms were used to normalize cepstra from the CSR corpus recorded with (i) Sennheiser (CLSTLK), (ii) Crown (PZM6FS) microphones. CLSTLK cepstra were used to generate the training corpus and PZM6FS cepstra were normalized. Scatter characteristics of the second cepstral coefficient for unnormalized and normalized cepstra indicate that the algorithm outperforms cepstral filtering techniques CMR and RASTA. The most notable feature in the scatter characteristics is the decrease in the skewness around the y=x (ideal) axis resulting from the finer adjustments in the PCU algorithm which can rotate as well as translate the data.
Future Work
The algorithm will in the near future be testted with the Texas Instruments speech recognition system as the ultimate measure of success of normalization is recognition accuracy. The supervised version of the PCU algorithm, known as Learning Vector Quantrization (LVQ), has been proved to be convergent. There is no such result for the PCU algorithm yet. It is an important research topic to determine the effect of different resolution schedules on the convergence of the algorithm. In particular, for implementation it is desirable to know how fast the codebook can converge to the true distribution when the test microphone belongs to a given class of microphones.