News Story
Who should Google Scholar update more often?
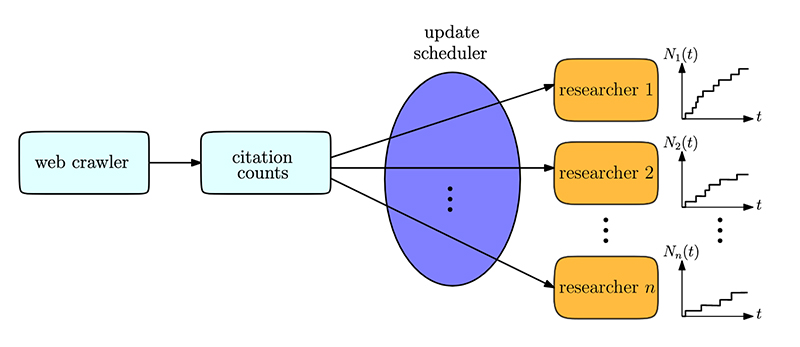
Web crawler finds and indexes scientific documents, from which citation counts are extracted upon examining their contents. Scheduler schedules updating citation counts of individual researchers based on their mean citations, and optionally, importance factors, subject to a total update rate. (Fig. 1 from the paper)
Google Scholar, a citation index, crawls the web to find and index various items such as documents, images, videos, etc. As it focuses on scientific documents, Google Scholar further examines the contents of these documents to extract out citation counts for indexed papers. Google Scholar then updates citation counts of multitudes of individual researchers.
Google Scholar is, of course, resource-constrained; it cannot update all researchers all the time. If Google can update only a fraction of all researchers, how should it prioritize the updating process? Should it update researchers with higher mean citation rates more often, as their citation counts are subject to larger change per unit time? Or should it update researchers with lower mean citation rates more often to capture rarer, more informative changes?
In a new paper, Who Should Google Scholar Update More Often?, Professor Sennur Ulukus (ECE/ISR) and her graduate student Melih Bastopcu, model the citation count of each individual researcher as a counting process with a fixed mean. They use a metric similar to the age of information: the long-term average difference between the actual citation numbers and the citation numbers according to the latest updates. Ulukus and Bastopcu show that, to minimize this difference metric, the updater should allocate its total update capacity to researchers proportional to the square roots of their mean citation rates.
That is, more prolific researchers should be updated more often, but there are diminishing returns due to the concavity of the square root function. In a more general sense, the paper addresses the problem of optimal operation of a resource-constrained sampler that wishes to track multiple independent counting processes in a way that is as up to date as possible.
Published February 24, 2020
Related Stories
Stories / January 13, 2023
Five Clark School authors part of new 'Age of Information' book

Stories / September 14, 2022
Alum Ahmed Arafa wins NSF CAREER Award

Stories / April 19, 2022
Bastopcu and Ulukus build model for real-time timely tracking...
Stories / October 6, 2021
Buyukates and Bastopcu win Best Student Paper Award at IEEE...

Stories / January 7, 2020
Researchers balance information quality and freshness in...
Stories / June 12, 2018
Ephremides leads new NSF Age of Information project

Stories / November 30, 2023
Barg honored with 2024 IEEE Richard W. Hamming Medal

Stories / November 30, 2023
Barg is PI for new quantum LDPC codes NSF grant

Stories / May 21, 2023
Narayan receives NSF funding for shared information work
Stories / March 14, 2023
Forthcoming information-theoretic cryptography book co-written...
