2023
Sherief M. Elsibaie, Bilal M. Ayyub, Jennifer F. Helgeson, Christina C. Gore, David T. Butry
This report demonstrates an example of loss amplification and risk aversion in benefit-cost analysis (BCA) for community resilience planning. The tool used is the NIST Economic Decision Guide Software (EDGe$) Online Tool, which assesses the economic feasibility of community resilience alternatives. Loss amplification arises from a catastrophe modeling method used to represent the increased costs associated with repair activity during a demand surge after a large catastrophe and could also be applied to mortality costs if the age of mortality is expected to skew younger. Risk aversion is a measure of a community’s (or other entity’s) preference to avoid uncertainty. Risk aversion parameters can be used to compute certainty equivalent payoffs from uncertain payoffs and specific levels of risk aversion. A fictitious case study of wildfire disaster planning of a wildland-urban interface (WUI) is employed to demonstrate these two model enhancements (i.e., loss amplification and risk aversion) and their effects on the economic indicator outputs from EDGe$. The presented case study evaluates a binary development choice related to the resilience of a large presidential library from the perspective of two neighboring communities
NIST Special Publication SP 1296
Papers presented at ASCE Inspire 2023 (Ayyub and multiple additional authors)
Freight Rail Network Topological Analysis Weighted by Hazmat Commodity Volumes, Traffic Density, and Population at Risk
Weighted Rail Network Topological Analysis: Efficiency, Eccentricity, and Related Attributes
Impacts of Energy Transformation on Coal Rail Transportation: Estimates and Projections for the Period 2005–2050
Freight Rail Network Topological Analysis Weighted by Hazmat Commodity Volumes, Traffic Density, and Population at Risk
Risk Tolerance and Attitudes in the Economics of Electric Power and Gas Utilities: Case of Wildfire for Community Resilience
Bilal Ayyub, Yujie Mao, Majed Hamed, Sherief Elsibaie, Magdy Elsibaie
The Federal Railroad Administration sponsored a team at the University of Maryland at College Park’s Center for Technology and Systems Management (CTSM) to develop methods and illustratively assess the weighted connectedness efficiency of U. S. freight railroad networks based on commodity volumes and examine node and link criticality for the entire network’s performance based on waybill data to inform planning decisions. Research was conducted from 2019 to 2022 at the CTSM.
U.S. DOT Federal Railroad Administration report
Bilal Ayyub, Yujie Mao, Majed Hamed, Sherief Elsibaie, Magdy Elsibaie
The Federal Railroad Administration sponsored a team at the University of Maryland at College Park’s Center for Technology and Systems Management (CTSM) to develop methods and illustratively assess the weighted connectedness efficiency of U. S. freight railroad networks based on commodity volumes and examine node and link criticality for the entire network’s performance based on waybill data to inform planning decisions. Research was conducted from 2019 to 2022 at the CTSM.
U.S. DOT Federal Railroad Administration report
2021
Lu Dai, Mark Hansen, Michael Ball, David Lovell
The authors apply machine learning algorithms to model the system delay and predict high delay days in the U.S. National Airspace System for the 2010s. A broader scope of factors that may affect the system delay is examined, including queueing delays, terminal conditions, convective weather, wind, traffic volume, and special events. They train models to relate the system delay to these features spatially and temporally, and compare the performance of penalized regressions, kernelized support vector regressions, and ensemble regressions.
14th USA/Europe Air Traffic Management Research and Development Seminar (ATM2021)
Yulin Liu, Mark Hansen, Michael Ball, Thomas Vossen
En route inefficiency is measured in terms of extra distance flown by an aircraft, above a benchmark distance that relates to the theoretical shortest distance route (great circle route). In this paper, the authors explore causal relations among en route inefficiency with multiple identified sources: convective weather, wind, miles-in-trail (MIT) restrictions, airspace flow programs (AFPs) and special activity airspace (SAA). They propose two mechanisms – strategic route choice and tactical reroute – to ascribe flight en route inefficiency to these factors.
Transportation Research Part B: Methodological
Michael Ball, Thomas Vossen
The researchers use the slot exchange concept as a starting point to present and analyze two advanced exchange mechanisms. They replace the current one-for-one exchange mechanism, i.e. compression, with a two-for-two exchange mechanism. Subsequently, they add the possibility of monetary side-payments to the exchange. Implementation of the the two-for-two exchange mechanism requires the solution of a mediator problem, which must determine the set of two-for-two offers to accept. The incorporation of monetary side payments represents a fundamental shift from barter to a true marketplace. Supporting such a marketplace requires the development of an appropriate auction mechanism. In both cases, the effectiveness of the exchange mechanisms should be measured by comparing the efficiency of the allocations the mechanisms can achieve with a globally optimal allocation. Each of these topics represents an interesting research challenge, which the authors address.
TRISTAN V: The Fifth Triennial Symposium on Transportation Analysis
2020
Yeming Hao, Sergio Torres, David Lovell, Michael Ball
Traffic flow systems that balance demand versus capacity at busy airports assign Controlled Times of Arrival (CTAs) to incoming flights. This paper evaluates a strategy to assign these CTAs based on user-provided priority lists. The user-provided priority is used to drive a slot swapping algorithm that looks for opportunities to rearrange the order of flights in the CTA queue in a way that decreases delay cost. The authors quantify potential savings by comparing the queue after swapping with the default first-come-first-served rule.
2020 AIAA/IEEE 39th Digital Avionics Systems Conference
Yeming Hao, David Lovell, Michael Ball, Sergio Torres, Gaurav Nagle
This paper proposes a flight scheduling scheme–2-opt-swap, which assigns controlled times of arrival (CTAs) for flights reaching the Freeze Horizon and allows certain slot swapping between different flights with the goal of reducing total controlled arrival delay cost over all carriers. The allowable swaps are predicated on models of carrier preferences following a Collaborative Decision-Making paradigm. Monte Carlo simulations were designed to prove the benefits of this new CTA scheduling scheme, compared to a baseline model of first-come-first-served discipline, which is currently used in Time-Based Flow Management.
2020 International Conference on Research in Air Transportation (ICRAT)
2023
Nariman Torkzaban, Anousheh Gholami, John Baras, Bruce Golden
The split delivery vehicle routing problem (SDVRP) is a relaxed variant of the capacitated vehicle routing problem (CVRP) where the restriction that each customer is visited precisely once is removed. Compared with CVRP, the SDVRP allows a reduction in the cost of the routes traveled by vehicles. The exact methods to solve the SDVRP are computationally expensive. Moreover, the complexity and difficult implementation of the state-of-the-art heuristic approaches hinder their application in real-life scenarios of the SDVRP. In this paper, the authors propose an easily understandable and effective approach to solve the SDVPR based on an a priori adaptive splitting algorithm (PASA).
International Transactions in Operational Research
2021
Lida Anna Apergi, Margret Bjarnadottir, John Baras, Bruce Golden, Kelley M Anderson, Jiling Chou, Nawar Shara
This is a study of the engagement of patients with heart failure with voice interface technology. In particular, the authors investigate which patient characteristics are linked to increased technology use.
JMIR mHealth and uHealth
2020
Lida Apergi, Bruce Golden, John Baras, Kenneth Wood
This research tackles the problem of outpatient scheduling in the cardiology department of a large medical center, where patients have to go through a number of diagnostic tests and treatments before they are able to complete a final interventional procedure or surgery. The authors develop an integer programming (IP) formulation to ensure that the outpatients will go through the necessary procedures on time, that they will have enough time to recover after each step, and that their availability will be taken into account.
Operations Research for Health Care
2020
Kushal Chakrabarti, Nirupam Gupta, Nikhil Chopra
The authors propose an iterative pre-conditioning method that significantly reduces the impact of the conditioning of the minimization problem on the convergence rate of the traditional gradient-descent algorithm.
arXiv.org
Tianchen Liu, Shapour Azarm, Nikhil Chopra
Two decentralized (multi-level and bi-level) approaches are formulated to solve multi-subsystem co-design problems, which are based on the direct collocation and decomposition-based optimization methods.
Journal of Mechanical Design
2023
Alexander Estes, Jean-Philippe Richard
This is a study of two-stage linear programs with uncertainty in the right-hand side in which the uncertain parameters of the problem are correlated with a variable called the side information, which is observed before an action is made. The authors propose an approach in which a linear regression model is used to provide a point prediction for the uncertain parameters of the problem. Using an approach called smart predict-then-optimize, rather than minimizing a typical loss function for regression, such as squared error, the authors approximately minimize the objective value of the resulting solutions to the optimization problem.
INFORMS Journal on Optimization
2023
Yijie Peng, Chun-Hung Chen, Michael Fu
A review of simulation optimization methods with a discussion of how these methods underpin modern artificial intelligence (AI) techniques. In particular, the authors focus on three areas: stochastic gradient estimation, which plays a central role in training neural networks for deep learning and reinforcement learning; simulation sample allocation, which can be used as the node selection policy in Monte Carlo tree search; and variance reduction, which can accelerate training procedures in AI.
INFORMS Tutorials in Operations Research
Xingyu Ren, Michael Fu, Steve Marcus
The authors review the literature on individual patient organ acceptance decision making by presenting a Markov Decision Process (MDP) model to formulate the organ acceptance decision process as a stochastic control problem. Under the umbrella of the MDP framework, they classify and summarize the major research streams and contributions. In particular, they focus on control limit-type policies, which are shown to be optimal under certain conditions and easy to implement in practice. Finally, we briefly discuss open problems and directions for future research.
Systems & Control Letters
Phillip Guo, Michael Fu
Global continuous optimization problems are often characterized by the existence of multiple local optima. For minimization problems, to avoid settling in suboptimal local minima, optimization algorithms can start multiple instances of gradient descent in different initial positions, known as a multi-start strategy. One key aspect in a multi-start strategy is the allocation of gradient descent steps as resources to promising instances. The authors propose new strategies for allocating computational resources, developed for parallel computing but applicable in single-processor optimization. Specifically, they formulate multi-start as a Multi-Armed Bandit (MAB) problem, viewing different instances to be searched as different arms to be pulled.
2022 Winter Simulation Conference (WSC)
Yi Zhou, Michael Fu, Ilya Ryzhov
This work considers policy evaluation in a finite-horizon setting with continuous state variables. The Bellman equation represents the value function as a conditional expectation, which can be further transformed into a ratio of two stochastic gradients. By using the finite difference method and the generalized likelihood ratio method, the authors propose new estimators for policy evaluation and show how the value of any given state can be estimated using sample paths starting from various other states.
2022 Winter Simulation Conference (WSC)
Yuanlu Bai, Shengyi He, Henry Lam, Guangxin Jiang, Michael Fu
Importance sampling (IS) is a powerful tool for rare-event estimation. However, in many settings, we need to estimate not only the performance expectation but also its gradient. In this paper, the authors build a bridge from the IS for rare-event estimation to gradient estimation. They establish that, for a class of problems, an efficient IS sampler for estimating the probability of the underlying rare event is also efficient for estimating gradients of expectations over the same rare-event set.
2022 Winter Simulation Conference (WSC)
Cheng Jie, Michael Fu
The authors study simulation-based methods for estimating gradients in stochastic networks. They derive a new method of calculating weak derivative estimators using importance sampling transform, with less computational cost than the classical method. In the context of M/M/1 queueing network and stochastic activity network, the researchers analytically show their new method will not result in a great increase of sample variance of the estimators.
arXiv.org
2022
Xingyu Ren, Michael Fu, Steve Marcus
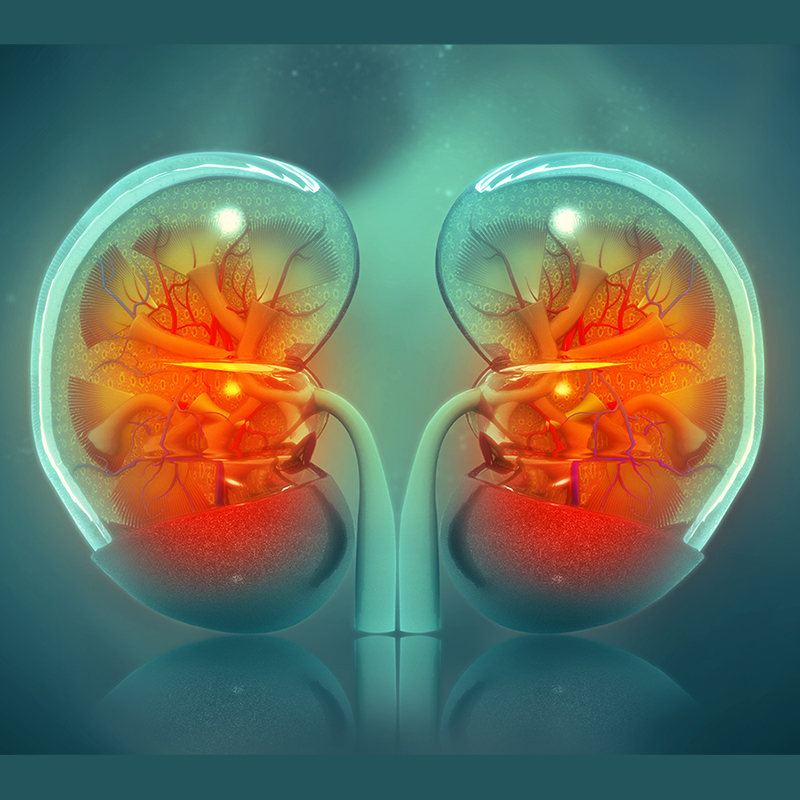
Incompatibility between patient and donor is a major barrier in kidney transplantation (KT). The increas- ing shortage of kidney donors has driven the development of desensitization techniques to overcome this immunological challenge. Compared with compatible KT, patients undergoing incompatible KTs are more likely to experience rejection, infection, malignancy, and graft loss. We study the optimal acceptance of possibly incompatible kidneys for individual end-stage kidney disease patients. To capture the effect of incompatibility, we propose a Markov Decision Process (MDP) model that explicitly includes compatibility as a state variable. The resulting higher-dimensional model makes it more challenging to analyze, but under suitable conditions, we derive structural properties including control limit-type optimal policies that are easy to compute and implement. Numerical examples illustrate the behavior of the optimal policy under different mismatch levels and highlight the importance of explicitly incorporating the incompatibility level into the acceptance decision when desensitization therapy is an option.
arXiv.org
Lei Lei, Yijie Peng, Michael Fu, Jian-Qiang Hu
Modeling dependence among input random variables is often critical for performance evaluation of stochastic systems, and copulas provide one approach to model such dependence. In the financial industry, the dependence among default times of different assets drives the pricing of portfolio credit derivatives, including basket default swaps and collateralized debt obligations. Copula sensitivities provide information about how changes in the dependence level affect the output. The authors study sensitivity analysis of elliptical copulas and Archimedean copulas using infinitesimal perturbation analysis, and an unbiased estimators is derived using conditional Monte Carlo (CMC) to address discontinuities that arise in portfolio credit derivatives.
European Journal of Operational Research
Yuanlu Bai, Shengyi He, Henry Lam, Guangxin Jiang, Michael Fu
Importance sampling (IS) is a powerful tool for rare-event estimation. However, in many settings, we need to estimate not only the performance expectation but also its gradient. In this paper, the authors build a bridge from the IS for rare-event estimation to gradient estimation. They establish that, for a class of problems, an efficient IS sampler for estimating the probability of the underlying rare event is also efficient for estimating gradients of expectations over the same rare-event set. They show that both the infinitesimal perturbation analysis and the likelihood ratio estimators can be studied under the proposed framework.
Proceedings of the 2022 Winter Simulation Conference
2021
Yijie Peng, Michael Fu, Jiaqiao Hu, Pierre l’Ecuyer, Bruno Tuffin
The authors apply the generalized likelihood ratio (GLR) methods in Peng et al. (2018) and Peng et al. (2021) to estimate quantile sensitivities. Conditional Monte Carlo and randomized quasi-Monte Carlo methods are used to reduce the variance of the GLR estimators. The proposed methods are applied to a toy example and a stochastic activity network example. Numerical results show that the variance reduction is significant.
INRIA's HAL multi-disciplinary open access archive
Shengyi He, Guangxin Jiang, Henry Lam, Michael Fu
In solving simulation-based stochastic root-finding or optimization problems that involve rare events, such as in extreme quantile estimation, running crude Monte Carlo can be prohibitively inefficient. To address this issue, importance sampling can be employed to drive down the sampling error to a desirable level. However, selecting a good importance sampler requires knowledge of the solution to the problem at hand, which is the goal to begin with and thus forms a circular challenge. We investigate the use of adaptive importance sampling to untie this circularity.
arXiv.org
2020
Jian Chen, Michael Fu, Wenhong Zhang, Junhua Zheng
Describes a new discrete-time Markov chain predictive model for the COVID-19 pandemic that provides a way to estimate parameters from available data and is computationally tractable both in terms of parameter estimation and in model output analysis. This model has been adopted by the first Shanghai assistance medical team in Wuhan’s Jinyintan Hospital, where the forecasts have been used for preparing and allocating medical staff, ICU beds, ventilators, and other critical care medical resources and for supporting medical management decisions.
Asia-Pacific Journal of Operational Research
2021
Kevin Chiu, David Anderson, Mark Fuge
The paper unpacks what it means to discover interesting behaviors or functions we do not know about a priori using data from experiments or simulation in a fully unsupervised way. Doing so enables computers to invent or re-invent new or existing mechanical functions given only measurements of physical fields (e.g., pressure or electromagnetic fields) without directly specifying a set of objectives to optimize.
Proceedings of the ASME 2021 International Design Engineering Technical Conferences & Computers and Information in Engineering Conference
Sangeeth Balakrishnan, Francis VanGessel, Zois Boukouvalas, Brian Barnes, Mark Fuge, Peter Chung
Deep learning has shown great potential for generating molecules with desired properties. But the cost and time required to obtain relevant property data have limited study to only a few classes of materials for which extensive data have already been collected. The authors develop a deep learning method that combines a generative model with a property prediction model to fuse small data of one class of molecules with larger data in another class.
Molecular Informatics
Scarlett R. Miller, Samuel T. Hunter, Elizabeth Starkey, Sharath Kumar Ramachandran, Faez Ahmed, Mark Fuge
Design researchers have long sought to understand the mechanisms that support creative idea development. However, one of the key challenges faced by the design community is how to effectively measure the nebulous construct of creativity. The social science and engineering communities have adopted two vastly different approaches to solving this problem, both of which have been deployed throughout engineering design research. This paper compares and contrasts these two approaches using design ratings of nearly 1000 engineering design ideas. While these two methods provide similar ratings of idea quality, there was a statistically significant negative relationship between these methods for ratings of idea novelty. The results also show discrepancies in the reliability and consistency of global ratings of creativity and provide guidance for the deployment of idea ratings in engineering design research and evidence.
ASME Journal of Mechanical Design
2019
Thurston Sexton, Mark Fuge
The paper directly models a cognitive process by which technicians may record work orders, recovering implied engineering knowledge about system structure by processing written records.
ASME 2019 International Design Engineering Technical Conference/Computers and Information in Engineering Conference
Keven Chiu, Mark Fuge
From engineering analysis and topology optimization to generative design and machine learning, many modern computational design approaches require either large amounts of data or a method to generate that data. This paper addresses key issues with automatically generating such data through automating the construction of Finite Element Method (FEM) simulations from Dirichlet boundary conditions.
ASME 2019 International Design Engineering Technical Conference/Computers and Information in Engineering Conference
2021
Stephanie Allen, Steven Gabriel, Daria Terekhov
The authors propose a hybrid method involving inverse optimization (IO) as a new approach for a road network’s traffic equilibrium problem and employ a modified two-stage stochastic model to make protection decisions using the IO information. They demonstrate the framework using two types of cost functions for the traffic equilibrium problem and show that accurate parameterizations of cost functions can change spending on protection decisions in most cases, when compared to assuming a uniform cost.
arXiv.org
Saeed Mohammadi, Mohammad Reza Hesamzadeh, Steven Gabriel, Dina Khastieva
Several engineering problems are modeled as linear bilevel programs (linear BLPs) where one problem (upper-level problem) has constrained variables which are optimal solutions of another problem (lower-level problem). The well-known single-level reformulation approach replaces the lower-level linear program with its Karush-Kuhn-Tucker optimality conditions and then linearizes the complementary slackness conditions employing the big-M technique. Although this approach is relatively simple and upstanding, it requires finding the disjunctive parameters (big-M). Regularly heuristic techniques are used to tune the big-M parameters. It is well-known that these techniques could fail, even though they are common. Finding the correct big-M parameters is computational challenging and it is recently shown to be NP-hard in several applications. This research presents a new parameter-free disjunctive decomposition algorithm tailored for the linear BLPs which (1) does not need finding the big-M parameters, (2) guarantees that the obtained solution is optimal to the given linear BLP, and (3) it is computationally advantageous. Our experience shows promising performance of the proposed algorithm in solving several linear BLPs.
31st European Conference on Operational Research (EURO2021)
2020
Jeffrey W. Herrmann, Kunal Mehta
Attributes provide critical information about the alternatives that a decision-maker is considering. When their magnitudes are uncertain, the decision-maker may be unsure about which alternative is truly the best, so measuring the attributes may help the decision-maker make a better decision. This paper considers settings in which each measurement yields one sample of one attribute for one alternative.
arXiv.org
Jeffrey W. Herrmann and multiple colleagues
From 2005–2013, Professor Jeffrey W. Herrmann (ME/ISR) worked on public health research with the U.S. Centers for Disease Control and Prevention (CDC); the Montgomery County, Maryland, Advanced Practice Center for Public Health Emergency Preparedness and Response; and the National Association of County and City Health Officials (NACCHO).
Specifically, Herrmann and his colleagues created mathematical and simulation models of mass dispensing and vaccination clinics (also known as points of dispensing or PODs). They also developed decision support tools to help emergency preparedness planners design clinics that have enough capacity to serve residents quickly while avoiding unnecessary congestion.
A poor clinic design has insufficient capacity and long lines of patients waiting for vaccinations or other services such as testing and triage. More patients require more space as they wait to receive treatment. If too many patients are in the clinic, they cause congestion, crowding, confusion, and the potential spread of disease. Herrmann's models and support tools help planners design clinics that have better patient flow and are able to process people more quickly and efficiently.
This research originally was developed with mass dispensing and vaccination clinics in mind. However, the principles behind the models and support tools are useful for those setting up emergency clinics to combat the COVID-19 pandemic. They are offered free of charge.
2022
Danae Mitkas, David Lovell, Sandeep Venkatesh, Seth Young
The researchers used home-built automated dependent surveillance-broadcast (ADS-B) data collection units to develop aircraft performance characteristics that could be used to model small airport capacity at general aviation airports. These units returned highly accurate and rich collected and processed data. The performance metrics were reasonable, valid, and applicable for use as inputs to future airport capacity models.
Transportation Research Record
2021
Danae Mitkas, David Lovell, Sandeep Venkatesh, Seth Young
This paper presents details of a novel hardware and software architecture for locally and automatically recording air traffic operations data at general aviation airports, including those that primarily serve smaller aircraft and may not have any other means, such as control towers, to collect such data.
14th USA/Europe Air Traffic Management Research and Development Seminar (ATM2021)
Lu Dai, Mark Hansen, Michael Ball, David Lovell
The authors apply machine learning algorithms to model the system delay and predict high delay days in the U.S. National Airspace System for the 2010s. A broader scope of factors that may affect the system delay is examined, including queueing delays, terminal conditions, convective weather, wind, traffic volume, and special events. They train models to relate the system delay to these features spatially and temporally, and compare the performance of penalized regressions, kernelized support vector regressions, and ensemble regressions.
14th USA/Europe Air Traffic Management Research and Development Seminar (ATM2021)
Danae Mitkas, David Lovell, Sandeep Venkatesh, Seth Young
This paper describes efforts to autonomously classify flight activities at small general aviation airports. The research team has Automatic Dependent Surveillance – Broadcast equipment installed at several small airports in the continental U.S. Data from these devices are consolidated in an Amazon Web Services cloud-based database and computing platform. A number of steps are taken to filter and clean the original data. Individual location records are stitched together to form flights. Supervised learning and clustering techniques are then applied to these flights to classify them according to their operations types. Because small airports are often connected to flight training schools, a particular focus of the project is classifying activities that are more typical of training procedures, and which would be less prevalent at airports where active training activities were not taking place. At the end of the classification process all detected flights receive a label indicating their operation type. This information can later be used to produce counts per operation per airport.
AIAA Aviation 2021 Forum
2020
Yeming Hao, Sergio Torres, David Lovell, Michael Ball
Traffic flow systems that balance demand versus capacity at busy airports assign Controlled Times of Arrival (CTAs) to incoming flights. This paper evaluates a strategy to assign these CTAs based on user-provided priority lists. The user-provided priority is used to drive a slot swapping algorithm that looks for opportunities to rearrange the order of flights in the CTA queue in a way that decreases delay cost. The authors quantify potential savings by comparing the queue after swapping with the default first-come-first-served rule.
2020 AIAA/IEEE 39th Digital Avionics Systems Conference
Yeming Hao, David Lovell, Michael Ball, Sergio Torres, Gaurav Nagle
This paper proposes a flight scheduling scheme–2-opt-swap, which assigns controlled times of arrival (CTAs) for flights reaching the Freeze Horizon and allows certain slot swapping between different flights with the goal of reducing total controlled arrival delay cost over all carriers. The allowable swaps are predicated on models of carrier preferences following a Collaborative Decision-Making paradigm. Monte Carlo simulations were designed to prove the benefits of this new CTA scheduling scheme, compared to a baseline model of first-come-first-served discipline, which is currently used in Time-Based Flow Management.
2020 International Conference on Research in Air Transportation (ICRAT)
2023
Bruce Golden, Eric Oden, S. Raghu Raghavan
Over the next two decades, Urban Air Mobility (UAM) Systems are anticipated to revolutionize the mass transportation industry. As envisioned presently, these systems will consist of electric vertical take-off and landing aircraft (eVTOLs) that operate from specially designed ports dispersed throughout a city. The authors consider the network logistics associated with the operation of a UAM system in its early phases, and focus on a problem of "routing and scheduling eVTOLs to maximize passenger throughput." Key challenges for providers are the temporal nature of the demand, time windows for customers, and battery management constraints of the eVTOLs. A three-index, arc-based formulation is developed which routes eVTOLs over a time-expanded network.
Annals of Operations Research
Bruce Golden, Eric Oden, S. Raghu Raghavan
This article considers a novel scheme for same-day delivery with a strong potential to reduce transportation costs. A delivery company has two distinct fleets for last-mile delivery: trucks with known (i.e., fixed) delivery routes leaving early in the day carrying one or more-day delivery packages, and shuttles leaving later in the day carrying same-day delivery packages. By allowing shuttles to intercept trucks and hand off packages for truck delivery it may be possible to leverage the unfinished portion of truck routes to shorten the delivery routes of the shuttles. This is the Rendezvous Vehicle Routing Problem. The authors present a mathematical formulation of the problem, as well as a column generation algorithm that can quickly find optimal solutions for instances with up to 200 nodes. They also develop and demonstrate the effectiveness of a specialized heuristic for use in larger instances with up to 1000 nodes. Their computational study validates the efficacy of truck-shuttle synchronization in this scheme, demonstrating an average savings of 20% across the test instances.
Optimization Letters
Rui Zhang, S. Raghu Raghavan
Last-mile delivery is a critical component of logistics networks accounting for approximately 30-35% of costs. As delivery volumes have increased, truck route times have become unsustainably long. To address this issue, many logistics companies, including FedEx and UPS, have resorted to using a “Driver-Aide” to assist with deliveries. In the “Driver-Aide Problem,” a truck is equipped with both a “driver” and an “aide.” The aide can assist the driver in two ways. As a “Jumper,” the aide works with the driver in preparing and delivering packages, thus reducing the service time at a given stop. As a “Helper," the aide can independently work at a location delivering packages, while the driver leaves to deliver packages at other locations and then returns. Given a set of delivery locations, travel times, service times, and the jumper’s savings, the goal is to determine both the delivery route and the most effective way to use the aide (e.g., sometimes as a jumper and sometimes as a helper) to minimize the total delivery time.
In this paper, the authors model this problem as an integer program with an exponential number of variables and an exponential number of constraints, and propose a branch-cut-and-price approach for solving it. Computational experiments are based on simulated instances built on real-world data provided by an industrial partner. More importantly, the results characterize the conditions in which this novel operation mode can lead to significant savings in terms of both completion time and cost. The results show that the driver-aide with both jumper and helper modes is most effective when there are denser service regions and when the truck’s speed is greater than or equal to 10 MPH. Coupled with an economic analysis, the authors come up with rules of thumb that could be used in practice. They find that service delivery routes with greater than 50% of the time devoted to delivery (as opposed to driving) provide the greatest benefit. These routes are characterized by a high density of delivery locations.
S. Raghavan preprint website
2022
Shubham Akshat, Liye Ma, S. Raghu Raghavan
This paper studies the deceased-donor liver allocation policies in the United States (U.S.). In the transplant community, broader organ sharing is believed to mitigate geographic inequity in organ access, and recent policies are moving in that direction in principle. The liver allocation policy has gone through three major modifications in the last nine years. Despite these modifications, geographic inequity persists. The authors illustrate that a policy that equalizes the supply (deceased donors)-to-demand (waiting list patients) ratios across geographies is better than Acuity Circles in achieving geographic equity at the lowest trade-off on efficiency metrics.
INFORMS Journal of Manufacturing and Service Operations Management
2020
Shubham Akshat, S. Raghu Raghavan, Sommer Gentry
Presents a new nonlinear integer programming model for U.S. liver transplant allocation a model that allocates donor livers to maximize minimum supply/demand ratios across all transplant centers. In simulations, the model reduces disparities and saves lives.
Raghavan preprint website
2019
Dilek Günneç, S. Raghavan, Rui Zhang
This paper focuses on the NP-hard “least-cost influence problem (LCIP)”: an influence-maximization problem where the goal is to find the least-expensive way of maximizing influence over a social network.
INFORMS Journal on Computing, Nov. 26, 2019
2020
Lida Apergi, Bruce Golden, John Baras, Kenneth Wood
This research tackles the problem of outpatient scheduling in the cardiology department of a large medical center, where patients have to go through a number of diagnostic tests and treatments before they are able to complete a final interventional procedure or surgery. The authors develop an integer programming (IP) formulation to ensure that the outpatients will go through the necessary procedures on time, that they will have enough time to recover after each step, and that their availability will be taken into account.
Operations Research for Health Care
2019
Daniel Lemkin, Benoit Stryckman, Joel Klein, Jason Custer, William Bame, Louis Maranda, Kenneth Wood, Courtney Paulson, Zachary Dezman
Integrating a safety smart list into the electronic health record decreases intensive care unit length of stay and cost.
Journal of Critical Care