News Story
Nau and colleagues develop APE, an integrated acting-and-planning system
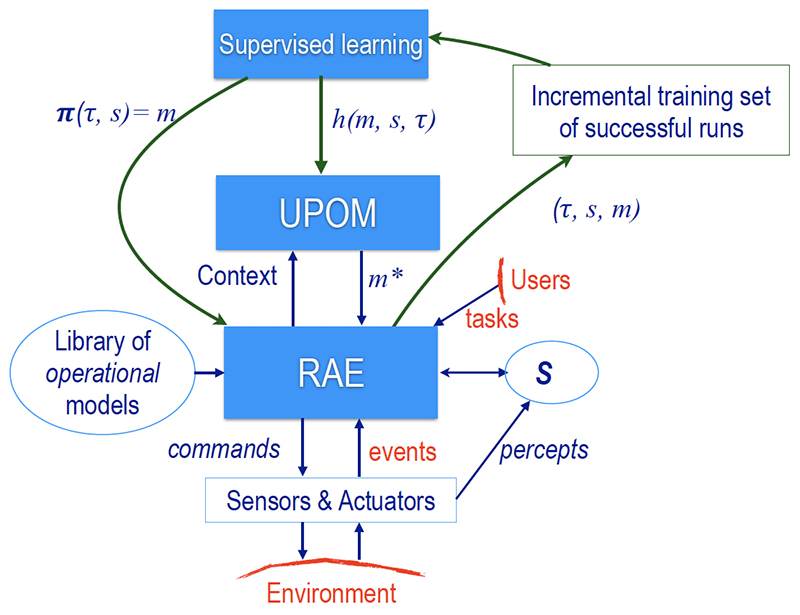
Integrating acting and planning is a long-standing problem in aritificial intelligence (AI). Despite progress beyond the restricted assumptions of classical planning, in most realistic applications simply making plans is not enough. Planning, as a search over predicted state changes, uses descriptive models to abstractly describe what actions do. Acting, as an adaptation and reaction to an unfolding context, requires operational models which tell how to perform actions with rich control structures for closed-loop online decision making. The problem is how to maintain consistency between the descriptive and operational models.
In APE: An Acting and Planning Engine, Professor Dana Nau (CS/ISR) and his colleagues have developed Acting and Planning Engine (APE), an integrated acting-and-planning system that addresses the consistency problem by using the actor’s operational models both for acting and for planning. The paper appears in Advances in Cognitive Systems 7, December 2019. In addition to Nau, the authors include Sunandita Patra (CS/ISR); Malik Ghallab of the Centre national de la recherche scientifique (CNRS), France; Paolo Traverso of the Fondazione Bruno Kessler (FBK), Trento, Italy.
APE uses hierarchical operational models to choose its course of action with a planner that uses Monte Carlo sampling over simulated executions. A collection of refinement methods offers alternative ways to handle tasks and react to events. Each method has a body that can be any complex algorithm. In addition to the usual programming constructs, the body may contain commands (including sensing commands), which are sent to a platform that executes them in the real world. The body also may contain subtasks, which can be refined recursively.
APE’s acting engine is based on an expressive, general-purpose operational language. To integrate acting and planning, APE extends a reactive acting algorithm to include a planner called APE-plan. At each point where it must decide how to refine a task, subtask, or event, APE-plan performs Monte Carlo rollouts with a subset of the applicable refinement methods. At each point where a refinement method contains a command to the execution platform, the module takes samples of its possible outcomes using a predictive model of what each command will do.
The authors’ experiments addressed multiple aspects of realistic domains, including dynamicity and the need for run-time sensing, information gathering, collaboration, and concurrent tasks. While APE shows substantial benefits in the success rates of the acting system, in particular for domains with dead ends, the authors are already designing, implementing and testing refinements to their system.
Published February 17, 2020
Related Stories
Stories / March 26, 2020
Planning and learning algorithms developed for refinement...
Stories / December 11, 2018
Clark School team wins AFRL funding for swarm autonomy planning...

Stories / August 14, 2025
New Research Helps Robots Grasp Situational Context

Stories / July 25, 2025
ISR Alum Quoted in CNN, WSJ on AI Risks

Stories / November 15, 2023
Reinforcement learning is a game for Kaiqing Zhang

Stories / October 16, 2023
CSRankings places Maryland robotics at #10 in the U.S.

Stories / August 18, 2023
NSF funding to Fermüller, Muresanu, Shamma for musical...

Stories / May 5, 2023
Two ECE Graduate Students Win 2023 UMD Three Minute Thesis...

Stories / March 2, 2023
Shneiderman: Faulty machine learning algorithms risk safety,...

Stories / February 24, 2023
UMD’s SeaDroneSim can generate simulated images and videos to...
