News Story
Stop—hey, what’s that sound?
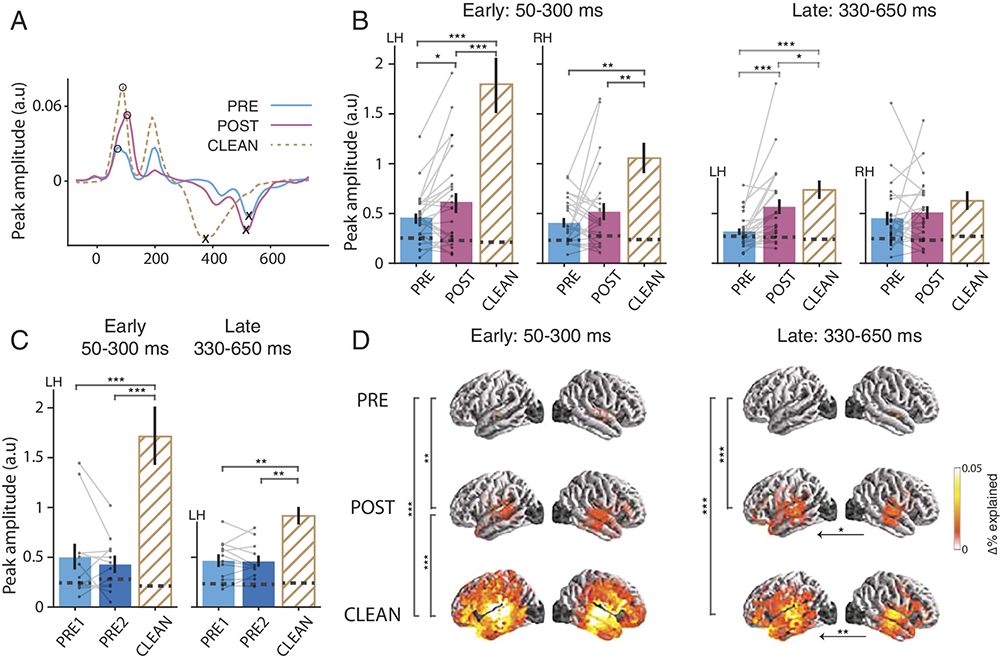
Summary of the results from the paper. A) Illustration of the main properties of speech processing that were used to model brain responses: detection of word onsets (green), prediction of the next phoneme based on the preceding phoneme sequence (purple) and competition of different word representations for recognition (cyan). B) Timing of brain responses associated with these stages, displayed as amplitude of the neural response over time relative to the events that are processed. C) Average brain location of the responses shown in B. D) The effect of listening to two speakers talking at the same time: the earlier acoustic stages process the sounds from both speakers, whereas the later, lexical stages track only the attended speech.
You’re walking along a busy city street. All around you are the sounds of subway trains, traffic, and music coming from storefronts. Suddenly, you realize one of the sounds you’re hearing is someone speaking, and that you are listening in a different way as you pay attention to what they are saying.
How does the brain do this? And how quickly does it happen? Researchers at the University of Maryland are learning more about the automatic process the brain goes through when it picks up on spoken language.
Neuroscientists have understood for some time that when we hear sounds of understandable language our brains react differently than they do when we hear non-speech sounds or people talking in languages we do not know. When we hear someone talking in a familiar language, our brain quickly shifts to pay attention, process the speech sounds by turning them into words, and understand what is being said.
In a new paper published in the Cell Press/Elsevier journal Current Biology, “Rapid transformation from auditory to linguistic representations of continuous speech,” Maryland researchers were able to see where in the brain, and how quickly—in milliseconds—the brain’s neurons transition from processing the sound of speech to processing the language-based words of the speech.
The paper was written by Institute for Systems Research (ISR) Postdoctoral Researcher Christian Brodbeck, L. Elliot Hong of the University of Maryland School of Medicine, and Professor Jonathan Z. Simon, who has a triple appointment in the Departments of Biology and Electrical and Computer Engineering as well as ISR.
“When we listen to someone talking, the change in our brain’s processing from not caring what kind of sound it is to recognizing it as a word happens surprisingly early,” said Simon. “In fact, this happens pretty much as soon as the linguistic information becomes available.”
When it is engaging in speech perception, the brain’s auditory cortex analyzes complex acoustic patterns to detect words that carry a linguistic message. It seems to do this so efficiently, at least in part, by anticipating what it is likely to hear: by learning what sounds signal language most frequently, the brain can predict what may come next. It is generally thought that this process—localized bilaterally in the brain’s superior temporal lobes—involves recognizing an intermediate, phonetic level of sound.
When we listen to someone talking, the change in our brain’s processing from not caring what kind of sound it is to recognizing it as a word happens surprisingly early. In fact, this happens pretty much as soon as the linguistic information becomes available.
Jonathan Simon
In the Maryland study, the researchers mapped and analyzed participants’ neural brain activity while listening to a single talker telling a story. They used magnetoencephalography (MEG), a common non-invasive neuroimaging method that employs very sensitive magnetometers to record the naturally occurring magnetic fields produced by electrical currents inside the brain. The subject typically sits under or lies down inside the MEG scanner, which resembles a whole-head hair drier, but contains an array of magnetic sensors.
The study showed that the brain quickly recognizes the phonetic sounds that make up syllables and transitions from processing merely acoustic to linguistic information in a highly specialized and automated way. The brain has to keep up with people speaking at a rate of about three words a second. It achieves this, in part, by distinguishing speech from other kinds of sound in about a tenth of a second after the sound enters the ears.
“We usually think that what the brain processes this early must be only at the level of sound, without regard for language,” Simon notes. “But if the brain can take knowledge of language into account right away, it would actually process sound more accurately. In our study we see that the brain takes advantage of language processing at the very earliest stage it can.”
In another part of the study, the researchers found that people selectively process speech sounds in noisy environments.
Here, participants heard a mixture of two speakers in a “cocktail party” scenario, and were told to listen to one and ignore the other. The participants’ brains only consistently processed language for the conversation to which they were told to pay attention, not the one they were told to ignore. Their brains stopped processing unattended speech at the level of detecting word forms.
“This may reveal a ‘bottleneck’ in our brains’ speech perception,” Brodbeck says. “We think that during speech perception, our brain considers the match between the incoming speech signal and many different words at the same time. Put a different way, the words compete for being recognized. It could be that this mechanism involves mental resources that can only process one speech signal at a time, making it impossible to attend simultaneously to more than one speaker.”
This study lays the foundation for additional research into how our brains interpret sounds as words. For example, how and when does the brain decide which word is being said? There is evidence that the brain actually sifts through possibilities, but it is currently unknown how the brain successfully narrows down the choices to a single word and connects it with the meaning of the ongoing discourse. Also, since it is possible to measure what fraction of the speech sounds are clear enough to be processed as being components of words, the researchers may be able to test listening comprehension when subjects can’t, or don’t understand how to, report it properly.
Citation
“Rapid transformation from auditory to linguistic representations of continuous speech,” by Christian Brodbeck, L. Elliot Hong and Jonathan Z. Simon. Current Biology. https://doi.org/10.1016/j.cub.2018.10.042
Funding
This work was supported by a National Institutes of Health grant R01-DC-014085 and by a University of Maryland Seed Grant.
Published November 30, 2018
Related Stories
Stories / September 26, 2023
New UMD Division of Research video highlights work of Simon,...

Stories / October 25, 2021
How does the brain turn heard sounds into comprehensible...
Stories / October 14, 2021
Internal predictive model characterizes brain's neural activity...
Stories / August 16, 2021
The brain makes sense of math and language in different ways
Stories / February 17, 2020
Fast estimation algorithm aids investigations of the cortical...
Stories / November 26, 2019
Study: brain’s circuitry can be altered even in adulthood
Stories / February 5, 2019
UMD researchers awarded $5.3M NIH BRAIN Initiative grant

Stories / October 18, 2016
It’s not your ears, it’s your brain

Stories / March 7, 2013
‘Cocktail party effect’ helps us focus in noisy environments

Stories / December 7, 2023
‘Priming’ helps the brain understand language even with...