News Story
AlphaGo family of AI programs grew from AMS simulation-based algorithms developed at UMD

In recent years, the Go-playing artificial intelligence AlphaGo and its successors AlphaGo Zero and AlphaZero have made international headlines with their incredible successes in game playing. They are part of a line of AI systems developed to beat humans at games like Go, checkers, chess, Scrabble and Jeopardy. Each successive challenge extends the boundaries of machine learning and its capabilities. The programs have been touted as evidence of the immense potential of artificial intelligence, and in particular, machine learning.
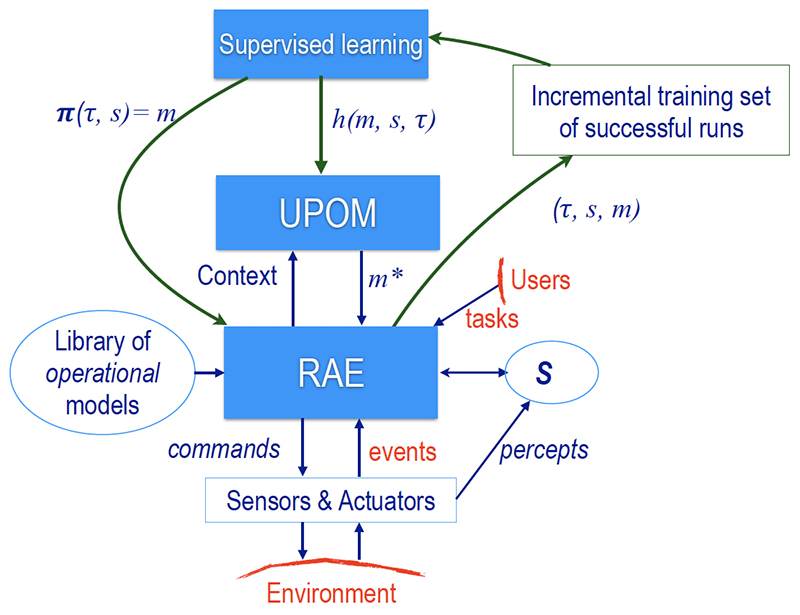
At the core of AlphaGo and its successors are the ideas related to adaptive multistage sampling (AMS) simulation-based algorithms for Markov decision processes (MDPs) first explored by four University of Maryland researchers in a 2005 Operations Research paper. Now, one of the researchers, Professor Michael C. Fu (BMGT/ISR), has written “Simulation-Based Algorithms for Markov Decision Processes: Monte Carlo Tree Search from AlphaGo to AlphaZero,” a review of the original ideas and the ensuing developments in the Asia-Pacific Journal of Operational Research, Vol. 36, No. 06, 1940009 (2019).
The deep neural networks of AlphaGo, AlphaZero, and all their incarnations are trained using a technique called Monte Carlo tree search (MCTS), whose roots can be traced back to an AMS simulation-based algorithm for MPDs published in Operations Research back in 2005.
“An adaptive sampling algorithm for solving Markov decision processes” was written by Institute for Systems Research (ISR) Postdoctoral Researcher Hyeong Soo Chang, Professor Michael C. Fu, Electrical and Computer Engineering (ECE) Ph.D. student Jiaqiao Hu, and Professor Steven I. Marcus (ECE/ISR). The idea was introduced even earlier in 2002.
In the current review article, Fu reviews the history and background of AlphaGo through AlphaZero, traces the origins of MCTS back to simulation-based algorithms for MDPs, and examines its role in training the neural networks that essentially carry out the value/policy function approximation used in approximate dynamic programming, reinforcement learning, and neuro-dynamic programming. Fu also includes discussion recently proposed enhancements that build on statistical ranking and selection research in the operations research simulation community.
Published December 17, 2019
Related Stories
Stories / July 21, 2021
Manocha talks AI on Federal News Network podcast

Stories / May 26, 2021
ISR faculty leading, playing key roles in ARL cooperative...

Stories / March 26, 2020
Planning and learning algorithms developed for refinement...
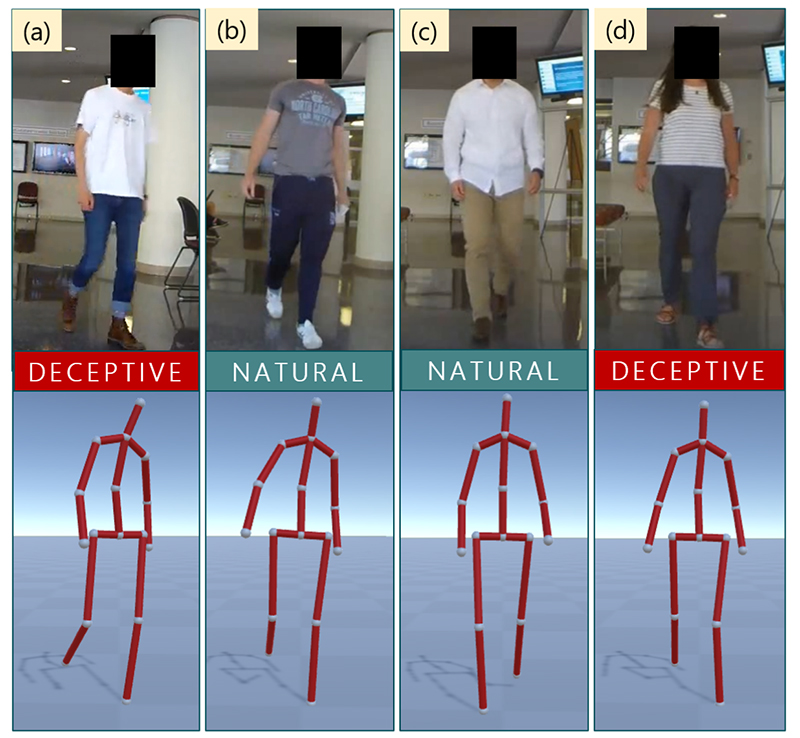
Stories / January 9, 2020
Who's walking deceptively? Manocha's team thinks they know.
Stories / July 9, 2018
New affiliate faculty Mark Fuge is expert in machine learning...

Stories / March 18, 2016
Maryland research contributes to Google’s AlphaGo AI system

Stories / March 23, 2026
UMD to Lead DARPA-Funded Effort to Accelerate Mathematical...

Stories / November 15, 2023
Reinforcement learning is a game for Kaiqing Zhang

Stories / October 21, 2022
'OysterNet' + underwater robots will aid in accurate oyster...

Stories / August 3, 2022
New system uses machine learning to detect ripe strawberries...
